Self-Attention Mechanism
This is an ongoing project being conducted with Anton Sugolov, Vardan Papyan, and Haoming Meng.
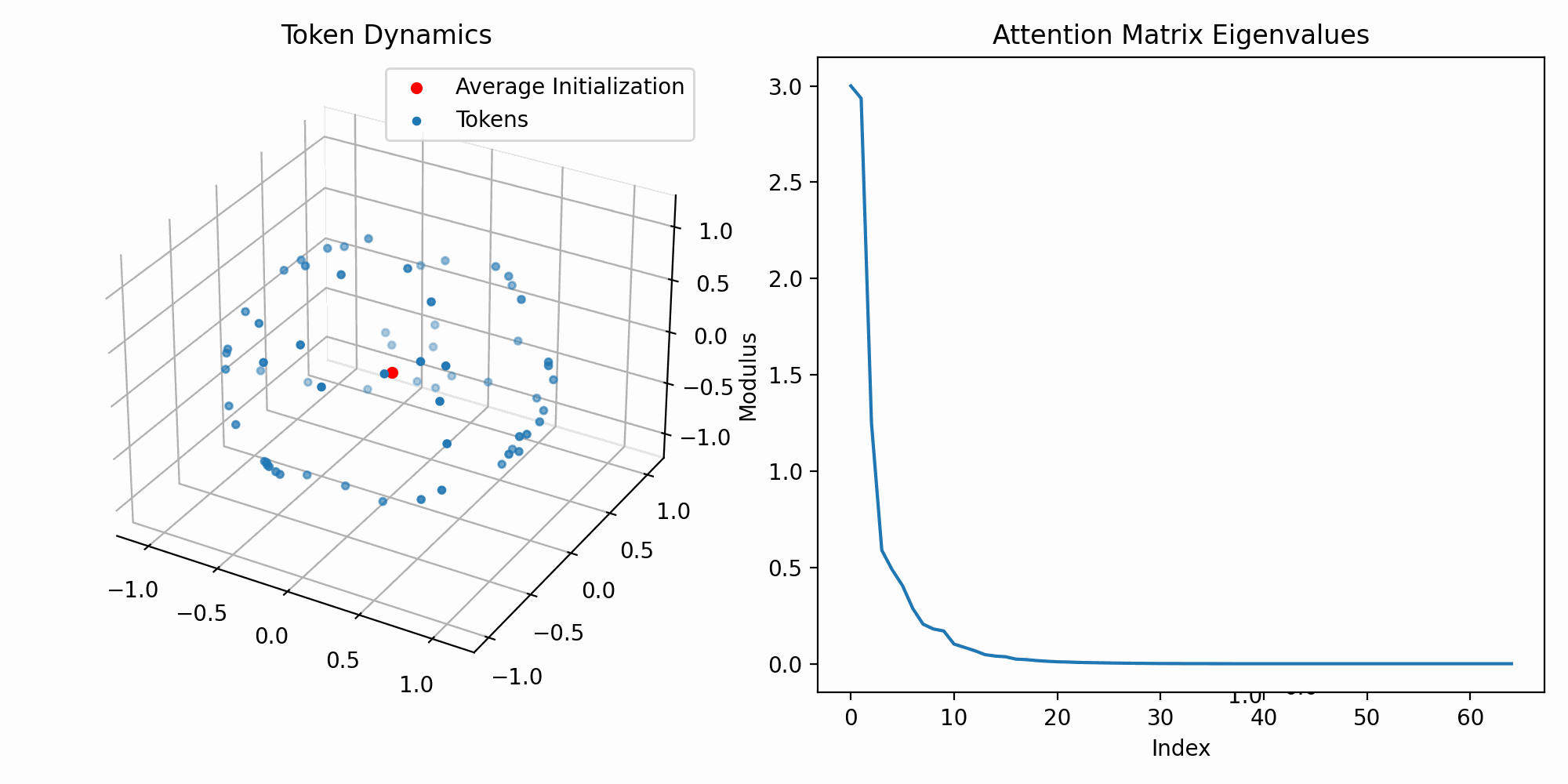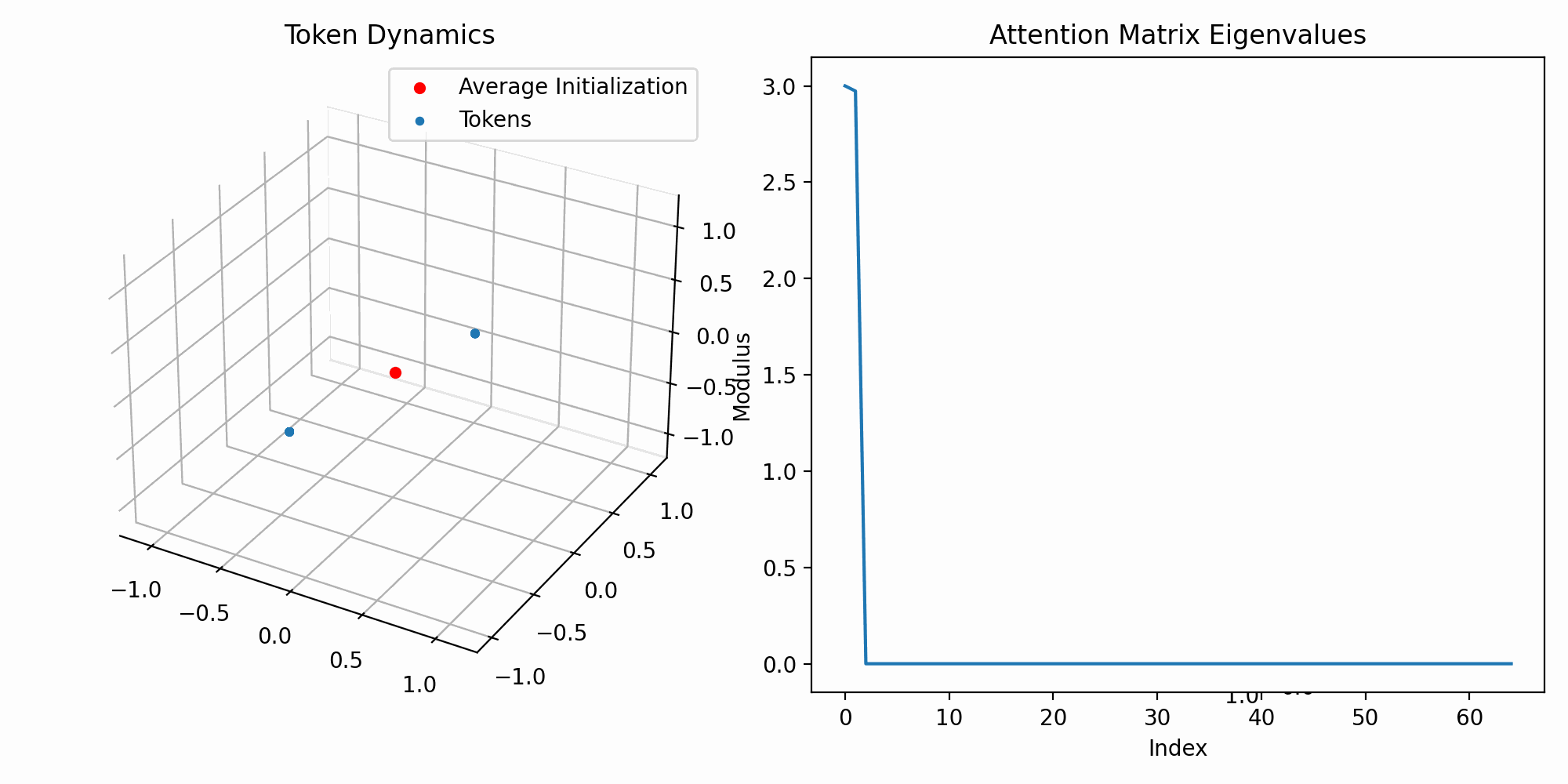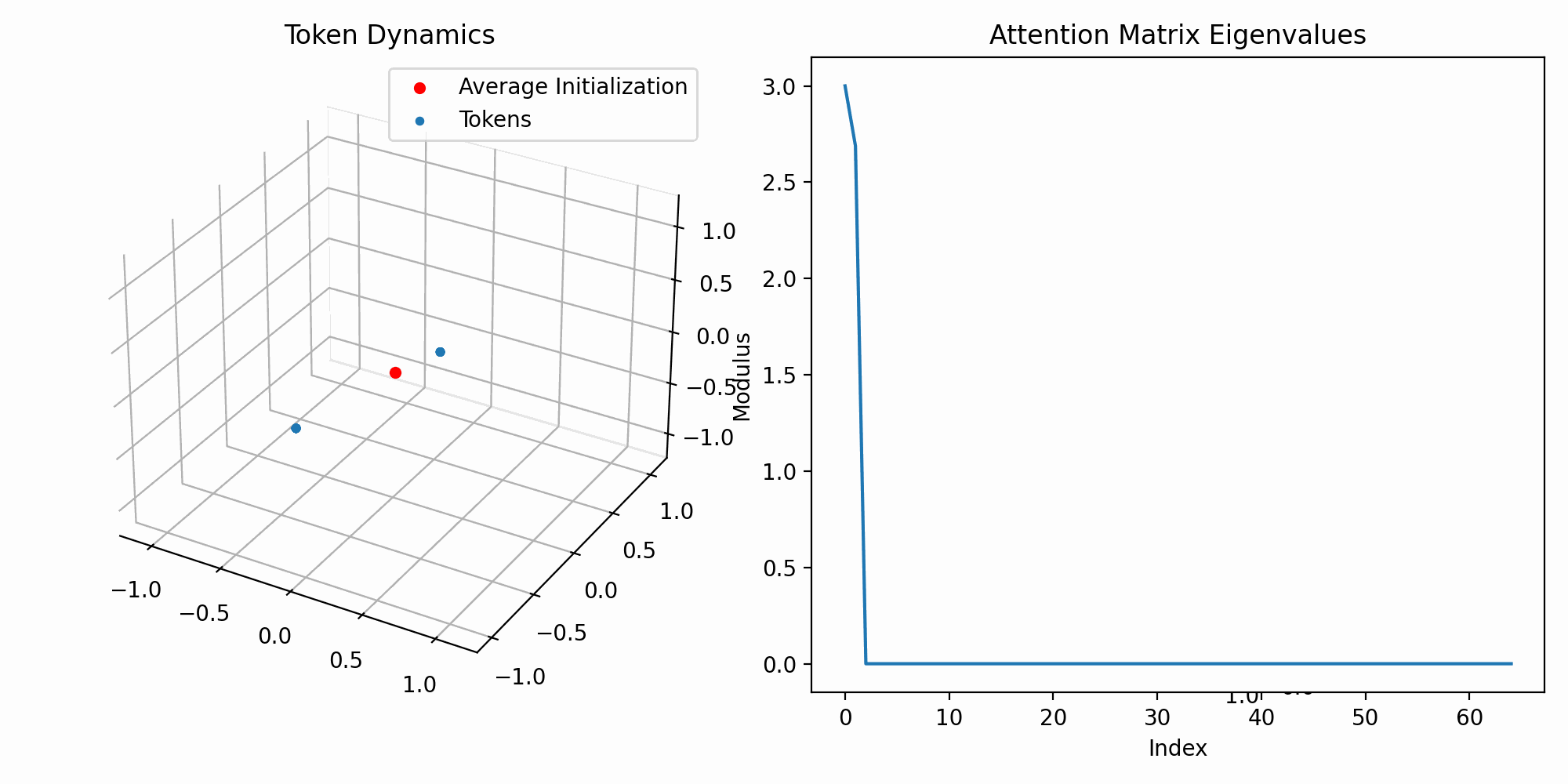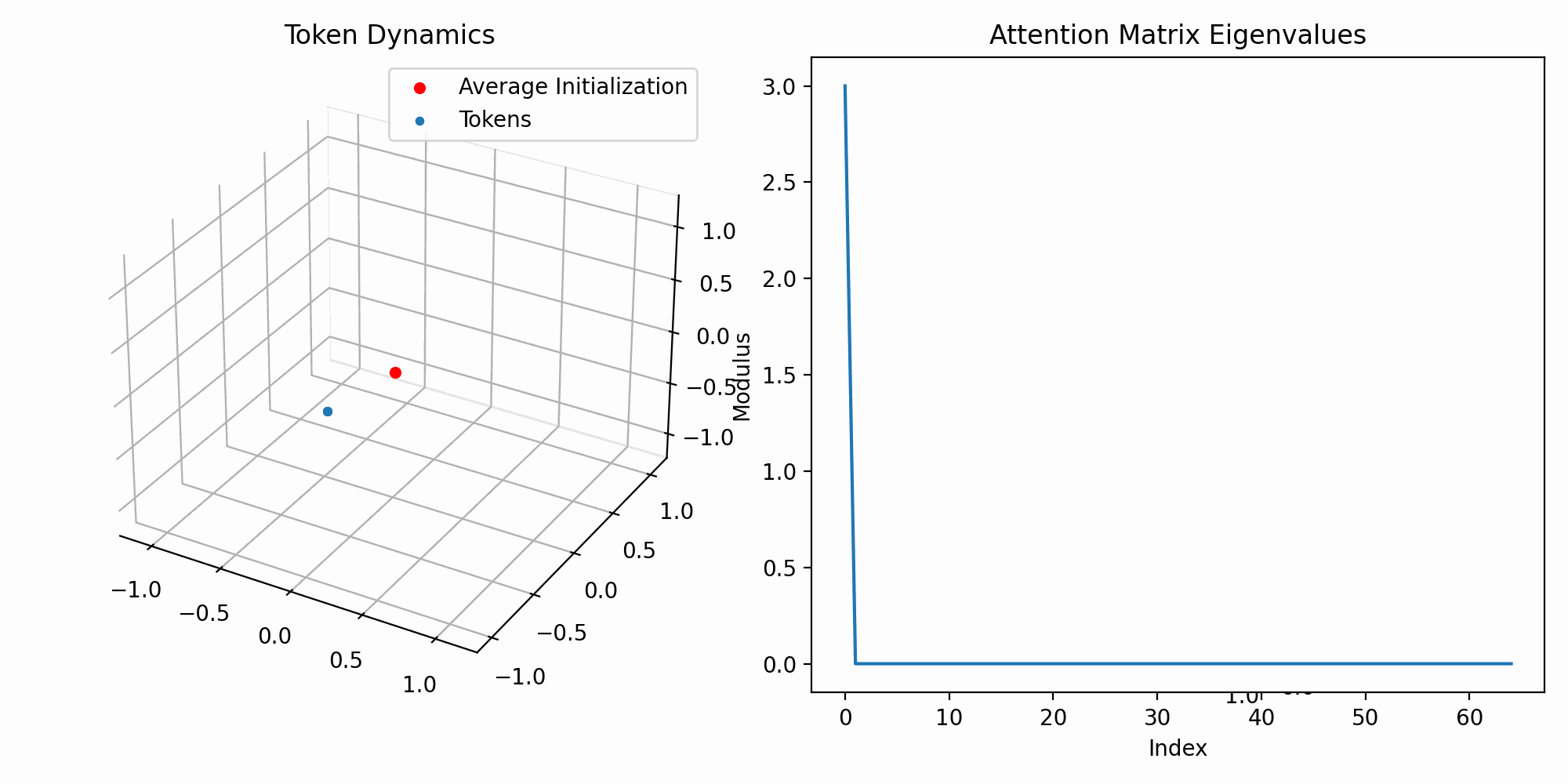
Our research is supported by both the Vector Institute and The University of Toronto. We are studying large language models (LLMs) with a focus on interpretability from a geometric and dynamical standpoint. In particular, we are interested in quantifying the dynamical behaviour of a set of tokens as they permeate through the model.
Our most recent work can be found here, which has been submitted to NeurIPS 2024.
Some previous work can be found here.
This entire project arose from a MAT1510 final assignment, the report and presentation slides from which can be found here and here respectively.
Check out the GitHub repository for this project here.
Here is an interesting gif from our early work: